| PageBox |
| Support | Map |
|
|
|
|
|
|
|
|
|
Patent search - search Patent organizationPatent lifecycleThe process for getting a patent is:
The granted patent protects the invention only in the application country. As we seen in the example above the patent can still be invalidated by a court as it was the case for the first PanIP patent. In USA it can also be re-examined by the patent office as it is currently the case for the Eolas patent and for other PanIP patents. For more information on the examination and re-examination you can read the re-examination page. Patent cooperation treatyTo get patent protection in other countries the inventor file one single patent application to a World Intellectual Property Organization (WIPO) office in which it designates the countries in which he wants to have patent protection. Thank to the Patent Cooperation Treaty (PCT) the patent application will be applied in parallel in these countries with the filing date of the original application country. Somewhat the same process as above is applied again:
This promotion process implies that governments agree on a common understanding of patents. This is defined by an agreement signed at the end of the Uruguay round, the Agreement on Trade-Related aspects of Intellectual Property rights (TRIPs). This document leaves some space for interpretation. You can look at a Review of the implementing legislation for government answers to questions asked by other governments. The fact is that software patentability is one of the most debated questions. You can download answers in a WordPerfect format that you can read with Word. Patent offices
The European Patent Office (EPO) is a prerequisite to European Union adhesion. However the EPO does not depend on European institutions (Commission and Parliament). The EPO site holds data on patents from 71 countries (45 millions at the beginning of 2004) and applications published by WIPO. Since 2003 their Online file inspection allows reading and downloading the correspondence between the between applicants and examiners thank to an Article 128 of the European Patent Convention, according to which the public is entitled to inspect the complete contents of the files relating to all European patent applications after they have been published. Since September 2004 the USPTO’s Patent Application Information Retrieval (PAIR) implements the same function. The USPTO hold data on US patents since 1790 and US applications published since 2001. You may look at http://www.piug.org/patdbase.html for a more comprehensive list of patent databases and at http://www.piug.org/patoffc.html for a fairly comprehensive list of patent offices. Patent searchPatent search is almost like Web search. The differences are:
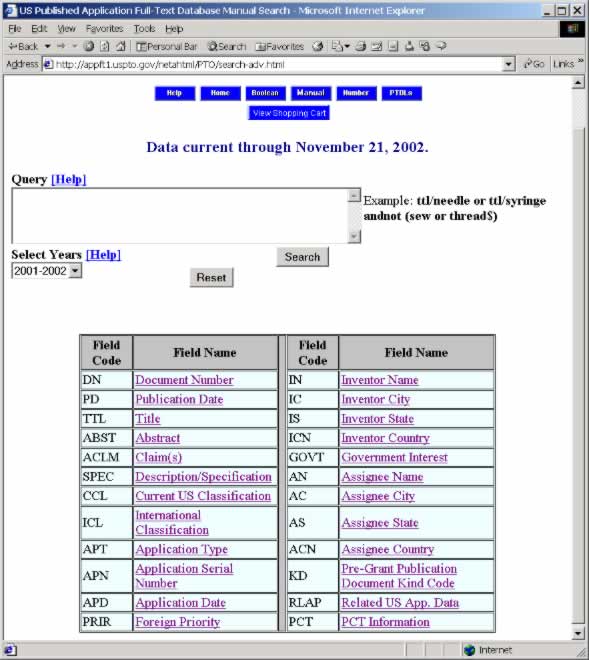
In this section we will take USPTO as an example. USPTO searchThe patent search page is http://www.uspto.gov/patft/index.html. Select Advanced search in Published Applications. You should get this:
Let’s assume we want to find patent applications related to PageBox. PageBox is a computer program that allows deploying applications to remote locations. The best keywords are computer, deployment, deploy and remote. If we were using a Web search engine, we would rather use Web service, deployment, J2EE, Java. Then we will restrict our research to the text of the claims. The query will be:
We get a list of 46 patent applications on Nov 26, 2002. 20020129129 (System and method for deploying and implementing software applications over a distributed network) is pretty close in some respect to PageBox. 20020129129 has been classified as 709/220, 709/218 by USPTO and G06F 015/16; G06F 015/177. We can think that if PageBox was patented it would also be in this classes: 709 stands for "MULTIPLE COMPUTER OR PROCESS COORDINATING", 220 for "Network computer configuring" and 218 for "Using interconnected networks." G06F 015/16 stands for " Combinations of two or more digital computers each having at least an arithmetic unit, a programme unit and a register, e.g. for a simultaneous processing of several programmes" and G06F 015/177 for "Initialisation or configuration control." Computer often but not necessarily exists in the claims of a PageBox related patent but we found that such a patent should be in 709/220. We improve our result with:
When a competitor claims to have a patent pending we use that sort of fast search. To identify patents that a project or product we use different method that consists:
Our advice is to forget common sense. A patent is a text made of sentences. The most effective solution is therefore to find texts that look like a reference text. It is basically the same concept but not the same process as the NSA patent 5,937,422, "Automatically generating a topic description for text and searching and sorting text by topic using the same." Note: In the example above we used "Advanced search in Published Applications" that allows displaying patent applications, which are no longer secret and not yet granted. On http://www.uspto.gov/patft/index.html you can also select "Advanced search in Issued Patents" to display granted patents. Which company filed the application?In case of 20020129129 and 5,937,422 the assignee name is the name of the company. However, quite often, the assignee name is the name of the patent attorney. If you suspect that the assignee name is not the company, look:
EPOTo look for US patents on the EPO site this is simple: add a us prefix and remove the commas. To look for 5,937,422 enter us5937422. For applications you may need to make two trials. 20020129129 is actually 2002/0129129. So you must try with and without the zero after the slash, so us20020129129 or us2002129129 (in this case us2002129129 is correct.) Inventor nameIf the "inventor" is an Intellectual Property specialist you are out of luck. Our experience is that there are three sorts of inventors in case of company application:
Our experience is that there are three types of inventors who design inventions:
This is easy to identify VP, C*O, living treasures and mavericks with Web search engines. Except for living treasures who like stability you need to find out where they were working at the date the application was filed. The living treasure or the maverick are often at the beginning of the inventor list and the VP/C*O are often at the end of the inventor list. Examples and drawingsIf the examples chosen in the detailed description of the preferred embodiment always relate to the same company there is a good chance that this company is the applicant. Look also at the figures. Quite frequently for business method and software application there are a couple of screenshots with the logo and the name of the company. Inventor addressThe city and the state where the inventors live are provided. With a site like MapQuest you can easily figure how distant are the inventors and which city is at a commuting distance from inventors. Usually geographical data are not sufficient to be sure that a patent was filed by a company for the reason that in USA companies working in a given sector are usually located in the same area. ToolkitText analysisWord count statistics give good result in patent search. The principle is to measure the word frequency in a reference text and to use the most frequently used words in the search. Related patents are likely to exhibit similar word frequencies. The results are better when the reference text is of the same type as the searched section: use most frequent words in reference claims to search on claims and use most frequent words in a reference description to search on description. If the reference text is written in Word you can use the WordCount macro of Cuckoo. This macro writes a report document like this:
This macro was designed primarily to improve the wording and the page performance on public search engines. Regarding the latter aspect you can find other tools on the Web. The goal is to facilitate the work of the search engines’ robots. These robots use word frequencies in the displayed text to determine the page subject, the idea being that a user who makes a search with the page’s most frequent words should find the page interesting. We wrote a standalone tool to measure word frequencies in html pages also called WordCount. WordCountWordCount is written in Java (JDK 1.3 or 1.4) and uses the Kizna HTML parser. HTMLParser is a library released under LGPL, which allows you to parse HTML (HTML 4.0 supported.) You can download HTMLParser from http://htmlparser.sourceforge.net.
WordCound is a command line tool. Assuming that you have included the JDK on your path and the WordCount.class directory and htmlparser.jar on your CLASSPATH you can measure the word frequencies in the 20020129129 patent application with:
Where the first parameter is the URL of the patent application on the USPTO site and excl.txt is a list of words to exclude from the measurement. We should get a report like this:
The report contains one line per word frequency that contains:
WordCount analyzes the text in the HTML elements. It excludes the words in excl.txt and applies a few English-dependent rules:
Therefore for other languages you probably need to slightly modify the code. We do not believe that an improved WordCount would be much more effective. Once you have generated the list you must manually select the unexpected frequent words to be the keywords of your queries. Search revisitedAdvanced search tools in Patent search engines and in Web search engines share a common drawback: they do not allow finding ALL documents of interest for you. It is usually a minor drawback in case of Web search but in case of patent search you need to be reasonably sure that your process infringes no patent. With the help of WordCount we can build an unordered keyword vector, for instance in case of 20020129129 V = { "server", "client", "download", "deploy$", "remote" } Then we can define a patent distance dV to the reference text, using the vector V as
Then we can look at the patents at a given distance or closer. The idea is to recognize that there is some uncertainty in the wording of patents. We can expect that related patents use most of the words in the keyword bag but not necessarily all of them. We can compare the lists found with this distance and with Boolean searches:
It would be nice if search engines could recognize a syntax like this: ["server", "client", "download", "deploy$", "remote" ]2 to mean that we are looking at all patents at a distance of 2 (that contain at least three words in { "server", "client", "download", "deploy$", "remote" }.) This syntax is not supported. Therefore we need to write our own tools:
Here is an example:
At each Uspto call we set one keyword as mandatory and the other keywords in an OR statement. Then Intersect combines the Uspto reports to display a list of patents sorted by growing distance (patents that contain all keywords, then patents that contain all keywords except one and so on.) UsptoUspto is written in Java (JDK 1.3 or 1.4.)
Uspto is a command line tool whose syntax is:
Assuming that you have included the JDK on your path and the Uspto.class directory on your CLASSPATH you can list patents whose class is 709/220 and whose claims contain "server" and either "client" or "deploy" or "remote" with:
Here is an example of keyword file:
Uspto calls the USPTO site in HTTP using the query parameter. Then Uspto parses the response and identifies the patent titles and URLs. Uspto calls again the USPTO site if the patent list cannot fit on one page. Next Uspto computes the patent title weights using the keyword file data. A line in the keyword file contains two or more fields:
The weight idea is that we only read patents whose title sounds interesting and that it is boring to read 50 and more patent titles. Weights aim to facilitate this first selection. When you write a keyword file keep in mind that a title contains between two and twenty and more words. You cannot be specific. Uspto creates two files:
IntersectIntersect is written in Java (JDK 1.3 or 1.4.)
Intersect is a command line tool whose syntax is:
Assuming that you have included the JDK on your path and the Intersect.class directory on your CLASSPATH you can compare reports issued by Uspto on November 30, 2002 with:
Here is a report returned with the command listed in the "Search revisited" section. The report contains four colums:
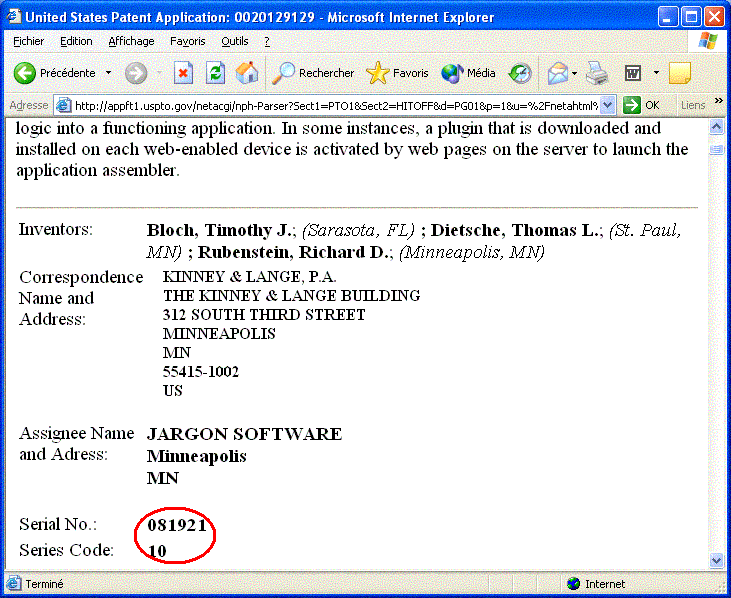
You can click on the application number to display the patent. However the link is a string like "http://appft1.uspto.gov/netacgi/nph-Parser?Sect1=PTO2&Sect2=HITOFF &u=/netahtml/PTO/searchadv.html&r=15&p=1&f=G&l=50&d=PG01 &S1=((server.CLM.+AND+709/220.CCLS.)+AND+((client.CLM.+OR+deploy$.CLM.)+OR+remote.CLM.)) &OS=aclm/server+and+ccl/709/220+and+(aclm/client+or+aclm/deploy$+or+aclm/remote) &RS=((ACLM/server+AND+CCL/709/220)+AND+((ACLM/client+OR+ACLM/deploy$)+OR+ACLM/remote))" which means that it can interpreted in a different way by the USPTO dynamic search engine the day after. Our experience is that these tools help finding patents of interest. Because they are simple you can adapt them easily to your needs. Then you can run them from time to time to check new patent applications. The key issue when we use or modify these tools is to keep a broad-enough spectrum to be reasonably sure that all patents of interest are in it and small enough to be able to analyze the patents. Prosecution analysisUSPTOYou may want to see the prosecution history of a patent (like 5,937,422) or an application 20020129129. For patents things are simple, just go on the PAIR (http://portal.uspto.gov/external/portal/pair), select Patent number in the Search method dropdown list and enter the patent number. For applications you must first find the correct application number. First go on http://www.uspto.gov/ and search application by number. In the application file you should have something like this:
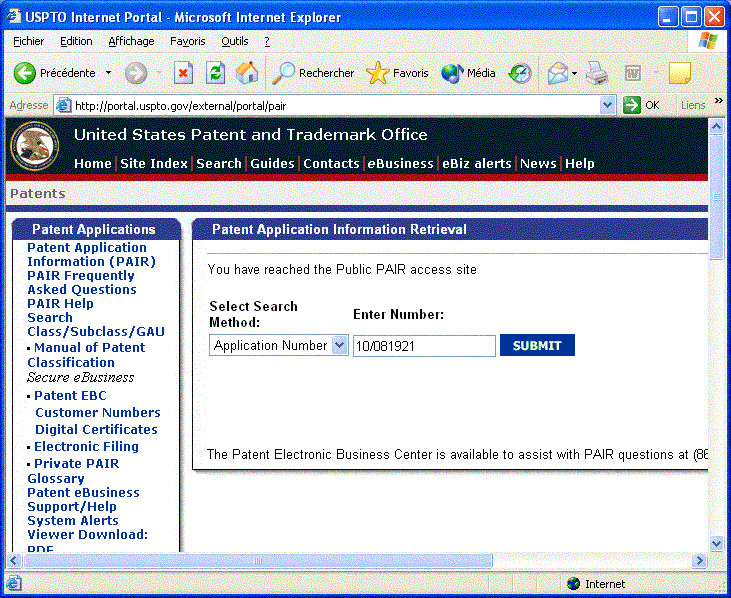
The correct application number is made of the Series Code followed by / and by the Serial No. In this case this is 10/081921. Now you can go on http://portal.uspto.gov/external/portal/pair and enter this number:
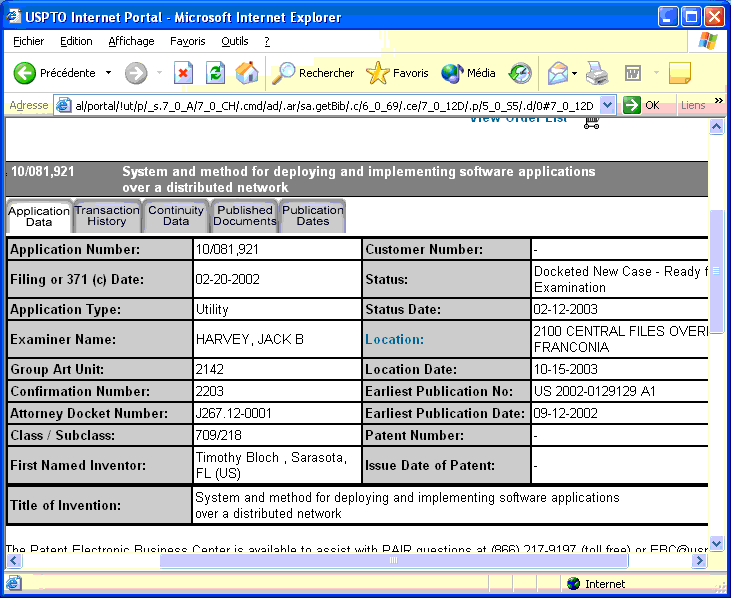
When you click on the Submit button you should get something like this:
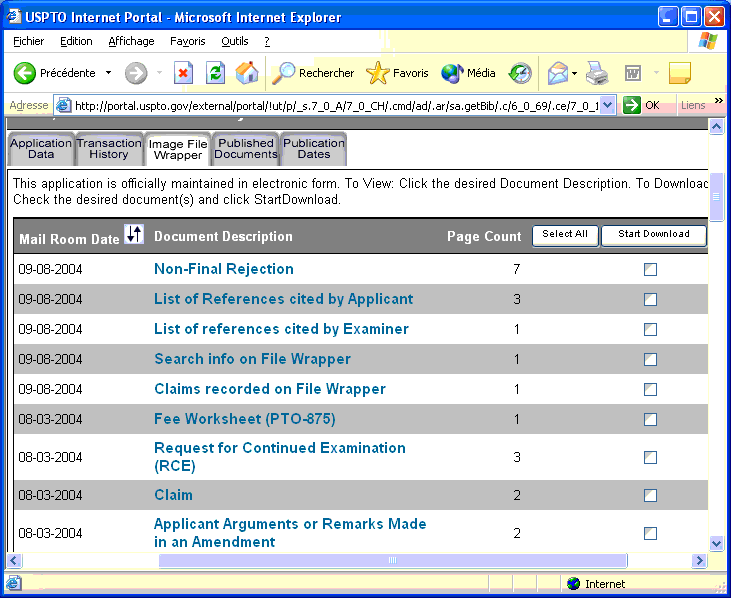
In this case you have five tabs. The transaction history contains what we called so far the prosecution history. The continuity data are quite useful to list the other applications in the same family. Published data usually points the patent text we have seen above. Because the examination has not yet started in this case (status = Ready for Examination) the image tab is missing. This is the case also when the patent has been granted. This image tab is present for the previous application (10/081921):
Click on a checkbox and then on the Start Download button to download the corresponding file in PDF format. It looks like the USPTO borrowed this not-so-obvious modus operandi from the EPO. Note that "Non-Final Rejection", "Applicant Arguments or Remarks Made in an Amendment" and the "Claim" coming with "Applicant Arguments or Remarks Made in an Amendment" are of interest:
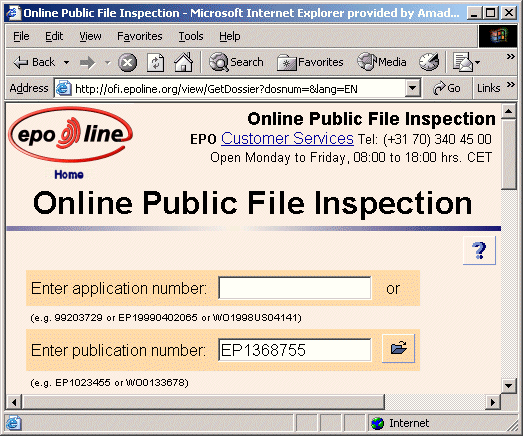
EPOThe EPO site contains prosecution files for applications and patents whose prosecution took place in Europe. To download these files go to http://ofi.epoline.org/view/GetDossier and enter a European application number, for instance EP1368755 (Method and system for providing message publishing on a dynamic page builder on the internet from IBM). You should have this:
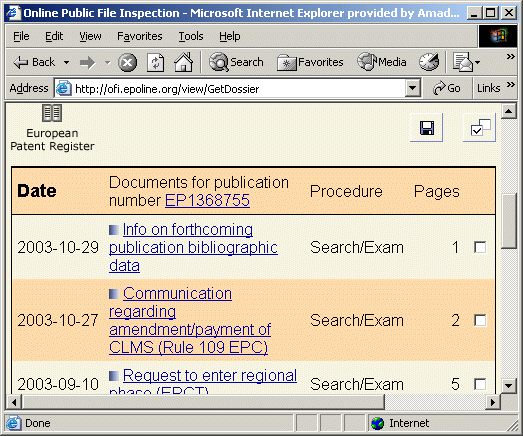
Click on the “Open this application” icon. You should get this:
Click on a checkbox and then on the Start Download button to download the corresponding file in PDF format. Of a particular interest are:
Open SourceAs you can see PageBox is reasonably distant from patents covering similar processes. Furthermore the development started at the end of 1999, which means that there is prior art to oppose to an attempt of patenting a similar process. Normally this happens silently. The patent examiner checks that claims are novel. For this checking the examiner uses patent databases and Internet archives like archive.org (Internet Way back machine) where many PageBox pages are recorded. If she finds that a claim is not novel the examiner rejects the patent application. Open Source developers do not necessarily check if their method or process is patented. This is understandable because the patentee usually sues the richest parties between the publisher and the product users. For instance PageBox is released with an LGPL license that includes a no warranty clause: "BECAUSE THE LIBRARY IS LICENSED FREE OF CHARGE, THERE IS NO WARRANTY FOR THE LIBRARY, TO THE EXTENT PERMITTED BY APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR OTHER PARTIES PROVIDE THE LIBRARY AS IS WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE LIBRARY IS WITH YOU. SHOULD THE LIBRARY PROVE DEFECTIVE, YOU ASSUME THE COST OF ALL NECESSARY SERVICING, REPAIR OR CORRECTION." Therefore a company that would believe that PageBox infringes its patent would sue PageBox users rather than us and those users would have no means to complain to us. Large firms frequently perceive this aspect as a significant drawback of Open source. We must however clarify this issue. The contract of a commercial program typically has a warranty and liabilities article that contains a clause like this: "The supplier must indemnify and hold harmless the customer against any claim concerning intellectual property relating to the program, provided that:
The buyer of a commercial product may be involved in a patent dispute and if it does not settle a transaction with the patentee the publisher may just reimburse the paid fees to the buyer and not the training and switching expenses. These expenses are usually higher for a commercial product than for an Open Source product. Patents Presentation Search Issues Strategies Business Methods Patentability Analysis MercExchange eBay Trial Reexamination Business view Granted patents Examination USPTO EPO PanIP Eolas 1-click family 1-click analysis 1-click prior art Trademark Copyright
Contact:support@pagebox.net |