| PageBox |
| Support | Map |
|
|
|
|
|
|
|
|
|
Grid API v2 MotivationThe first version of the Grid API supports two transport modes, UDP (which can be multicast) and SMTP. For the new PageBox deployment mode described in the Installation API document and based on the Grid API both UDP and SMTP are often not suitable:
Therefore we need to support a TCP transport mode. This TCP mode must be:
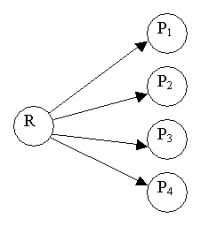
We can need a SOAP transport mode based on the same concept to go through the firewalls. ProblemIn the initial PageBox deployment model the Repository sends the archive (Web application, control) to the first PageBox and then to the second PageBox and so on:
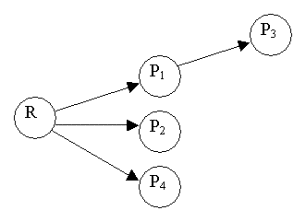
Sending the archive in parallel to the different PageBoxes would only give a marginal benefit: in case of large archives the Repository already uses most of the bandwidth. This distribution mode is simple and robust. The Repository knows immediately which PageBoxes it failed to deploy to. But this mode is not scalable. ApproachThe best solution is to give a relay capability to PageBox: the Repository sends the archive to a set of PageBoxes. Then these PageBoxes send the archive to other PageBoxes and so on.
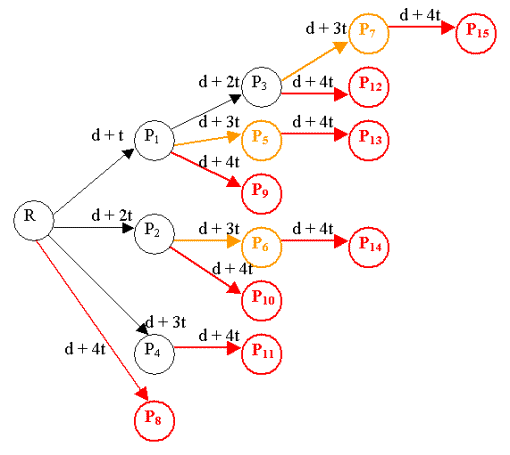
As we can see on this example the performance is better: Assuming a constant transfer time t and a deployment time d, at d + t we have deployed on P1, at d + 2t we have deployed on P2 and P4 and at d + 3t we have completed the deployment whereas the initial solution requires 4t (number of PageBoxes * t). When the list of subscribing PageBoxes grows the number of relay PageBoxes also grows: the solution is also more scalable. The deployment time is minimal when we browse the graph like this:
At each iteration every node (Repository of PageBox relay) deploys the Web archive on an adjacent node, which multiplies by two the number of nodes. Therefore we deploy the archive one time at d + t, two times at d + 2t, four times at d + 3t and eight times at d + 4t. Then we have deployed on 15 PageBoxes. At t + 10 we deploy on 29 PageBoxes and the Web archive is installed on 1023 PageBox hosts. Algorithm
To perform the first deployment the Repository selects a target P1 in the subscriber list. Then it divides the remaining subscriber list by two. It puts P3, P5, P7, P9, P12, P13 and P15 in the deployment request to P1.
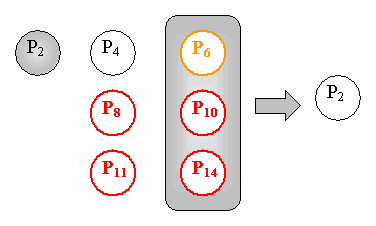
To perform the second deployment the Repository selects a target P2 in the remaining subscriber list. Then it divides the remaining subscriber list by two. It puts P6, P10, and P14 in the deployment request to P2.
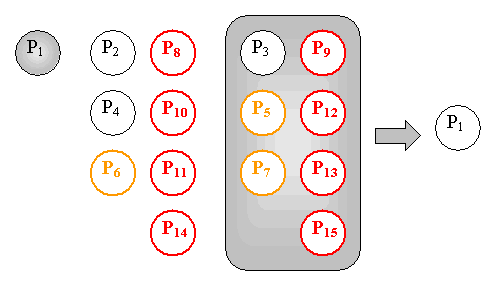
To perform the third deployment the Repository selects a target P4 in the remaining subscriber list. Then it divides the remaining subscriber list by two. It puts P11 in the deployment request to P2. Error handlingThe Repository and the relays make synchronous requests. When the Repository gets an error or a timeout condition it sets the corresponding subscriber in "Pending deploy" state. Otherwise it sets the corresponding subscriber in “Deployed" state. When a relay gets an error or a timeout condition it sends a Failure notification to the Repository. Then the Repository sets the corresponding subscriber in "Pending deploy" state. Otherwise it sends a Success notification to the Repository. Then the Repository sets the corresponding subscriber in “Deployed" state. The notification can fail for instance because the Repository is no longer running. The notification also uses the Grid API and is sent in TCP first. In case of failure the notification is retried in SMTP. When it restarts the subscriber reads its notification mails in POP3. Therefore the Repository has to process a large number of notifications: (subscriber_nb - 1)/2 + ((subscriber_nb – 1)/2 - 1)/2... which tends to subscriber_nb. It is not a problem in deployment because notification messages are small and their handling is very simple. Furthermore a relay PageBox uses a single TCP connection for all its notifications The Repository doesn’t know and doesn’t need to know except at retry time if a deployment is completed. When a subscriber asks a deployment the Repository sets the archive subscribers in a "Maybe" state. When a PageBox calls RepoQuery to get the lists of the archive subscribers the Repository returns the list of the subscribers in "Deployed" state. At retry time the Repository retries the deployment only to the subscribers in "Pending deploy" state. Our approach is scalable and provides a shortened deployment time. It has a small bandwidth overhead. However it requires almost 50% more connections and almost two times more messages. Therefore it should be used only for big messages (above a ceiling, typically 64KB). For this reason relaying is not used for undeploy and the Repository still send undeploy requests to all subscribers. Relaying is also not used for archive update (redeploy) when the Delta between the versions is below the ceiling. See the Installation API document for more information about the Delta update. TCP Grid APIThe deployment algorithm is also useful for Grid API purposes. In most cases the source requests are much bigger than the target responses:
Java PHP .NET
Contact:support@pagebox.net |
|