| PageBox |
| Support | Map |
|
|
|
|
|
|
|
|
PageBox Grid
If you are not familiar with Grid computing idea you can read "The Grid: Blueprint for a New Computing Infrastructure" edited by Ian Foster and Carl Kesselman at Morgan Kaufmann. I had a trainee one year ago, Leo Tingvall who wrote a thesis, which is a good introduction.
For years designers try to prove the value of their ideas through comparisons with ideas that worked in other domains. Design patterns authors claim to reuse an architect idea. For year we heard managers who want to industrialize software development. In the same way grid authors try to find grid roots in railways and electric power grids.
It is not the same thing. A computational grid is much cheaper and much harder to use than an electric grid:
Consider for instance how easy it is to measure electricity consumption and how hard it is to measure resource consumptions.
Consider how easy it is to secure an electric device with a fuse and how hard it is to secure a computer against errors and viruses.
Consider how cheap it is to write a program and to spread it around the world. Consider how expensive it is to build 1000s railway stations and to hire their staff.
Electricity is electricity. The power station that produced it doesn't matter. It is not the same thing to write a program to run on a PC or to use resources scattered around the country.
Grid computing is a new buzzword. Technology and even products existed before. Then we were speaking about Global Operating Systems, Distributed computing... Grid computing borrows to middleware (Tuxedo, CORBA). The real and specific problem that underlies the Grid concept is coordinated resource sharing and problem solving in dynamic, multi-institutional virtual organizations.
Grid architecture has five layers:
Fabric. The Fabric layer provides the resources to which shared access is mediated by Grid protocols. To be useful in a Grid context, Fabric must implement an enquiry mechanism to discover resource structure, state and capabilities and a resource management mechanism to provide a control of the quality of service. Fabric must control computational resources, storage resources, network resources, code repositories and catalogs
Connectivity. The connectivity layer defines core communication and authentication protocols
Resource. Resource defines protocols (and APIs and SDKs) for the secure negotiation, initiation, monitoring, control, accounting, and payment of sharing operations on individual resources. The Resource layer gives access to data, computation, information about the system structure, state and performance
Collective. Collective components manage interactions between collections of resources.
Application
Grid is appealing because:
More powerful a computer is, more expensive its MIPS, megabytes and IOs are.
Network is not necessarily a problem either we have a fast LAN or just because the processing requires few data exchanges
"When the network is as fast as the computer's internal links, the machine disintegrates across the net into a set of special purpose appliances." Says a Gilder Technology Report. Network throughput now tends to grow even faster than computer speed. It is generally believed that sometime in the future the Moore law (2 time faster every 18 months) will no longer apply to computers. Though it can be like oil shortage, there is a fact, which is that in computer industry small fishes always eat big ones. Unix servers killed supercomputers. CMOS mainframes killed ECL mainframes. The difference in processing power between a PDA and a PC is already shrinking.
However a higher throughput doesn’t necessarily imply a higher speed. On Internet when we must exchange large numbers of small messages latency is more important. Latency is caused by routers and routers are computers. The long-term solution is therefore to distribute the workload to large sets of computers as close as possible to each other to avoid routing. We will need to cache more and better than we do today.
We need something reliable and easy to install and configure. We believe that the processing power will move from the corporate glasshouses to the ASPs and to the user PCs. To enable that evolution we need a set of solutions:
Communication | Solution |
|---|---|
User PC to User PC | P2P |
Web server to Web server | PageBox |
Computer centers connected by fast links | Grid |
PageBox needs a Grid capability:
To host scalable Web services
To address effectively problems such as cache synchronization
This document describes the PageBox Grid function.
Grid computing applies the resources of many computers in a network to a single problem at the same time. Grid computing requires the use of software that can divide and farm out pieces of a program to as many as several thousand computers. Grid computing can be thought of as distributed and large-scale cluster computing and as a form of network-distributed parallel processing.
The idea is to offer in computational grids the same computer services as the conventional computers.
Conventional computers provide services that involve shared resources.
Then a computation includes the following steps:
Authentication designed to establish the user identity
Authorization that establishes the right of the user to get resources and especially to run processes
Communication with other processes using shared memory, messages or RPC protocols
Control of activities, for instance to suspend, resume or terminate processes
Resource acquisition and use (disk space, memory, requests)
Accounting that keeps track of the resource consumption
The conventional computer implements a resource allocation policy and implements a scheduling dealing with competing demands and quality of service requirements.
Parallel programming models find their origin in parallel processors and Flynn taxonomy:
SIMD: Single Instruction Multiple Data. Vector/Array processor
SPMD: Single Program Multiple Data
MIMD: Multiple Instruction Multiple Data
One node (typically the requestor node) acts as the controlling master for the parallel application and sends pieces of work out to worker nodes. The worker node makes the computation and sends the result back to the master node. The master has a pool of work that needs to be done, so it assigns the next piece of work out to the next worker that becomes available.
Because this model only requires one messaging request per piece of work, it can be effective even on high latency networks and doesn't require a high performance API.
A parallel application designed for the master-worker model has three steps:
Work slicing
Work distribution
Work merging
In some cases we must distribute. Let's consider the case of document search.
You have a document on your machine and you need to find similar documents in your organization. You define an algorithm to measure a distance between two documents. Then you use the Master-Worker model to distribute your search code to the document repositories in your organization. Your workers return the documents at the shortest distance of your reference document and your master displays them.
You can see workers and the example above as coarse-grained Single Program Multiple Data (SPMD) model.
Let's consider a simple example of code:
... Vector v = new Vector(); /* read data */ Iterator it = v.iterator(); while(it.hasNext()) { Zorglub z =(Zorglub)it.next(); process(z); } |
In standard programming we will process sequentially all Zorglub instances.
With SPMD, we distribute the process requests among the available workers and the processing of the Zorglub instances will run in parallel.
The model is effective if the messaging cost is smaller than the processing cost.
It can imply:
A fast network (at least 100 Mbps Ethernet, typically SCSI or Gigabit Ethernet)
A high-performance messaging API
Dedicated machines
Multiple Instruction Multiple Data architectures consist of a number of processors that can each execute individual instruction streams. They can use a shared memory or distributed memories. In the latter case each processor has its own memory.
In a Grid architecture there is no hardware cost but processors have necessarily their own memory. In order to access remote data the processors must communicate via explicit message passing.
A Grid architecture is intrinsically a MIMD architecture that we use most of the time in SPMD mode with a Master-Worker model.
You can find a comparison of PVM and MPI at http://www.epm.ornl.gov/pvm/PVMvsMPI.ps. Today MPI is more popular.
The PVM computing model is simple yet very general, and accommodates a wide variety of application program structures. The programming interface is deliberately straightforward, thus permitting simple program structures to be implemented in an intuitive manner. The user writes his application as a collection of cooperating tasks. Tasks access PVM resources through a library of standard interface routines. These routines allow the initiation and termination of tasks across the network as well as communication and synchronization between tasks.
The PVM message-passing primitives are oriented towards heterogeneous operation, involving strongly typed constructs for buffering and transmission. Communication constructs include those for sending and receiving data structures as well as high-level primitives such as broadcast, barrier synchronization, and global sum.
PVM has three key principles:
A simple API allowing messaging, virtual machine control, task control, event handling with only about 60 library routines
Transparent heterogeneity. Programs can interoperate across different machine architectures, networks, programming languages and operating systems.
Dynamic system configuration
Drawbacks:
PVM doesn't support pipelining. It requires packing messages in XDR format.
PVM messaging assumes synchronous messaging.
With Harness PVM should evolve toward a pluggable computing environment that could be called Generalized plug-in machine (GPM). You can read http://www.csm.ornl.gov/harness/nextGen.ps for more information.
Here is an example of PVM program.
#include <pvm3.h> /* Maximum number of children this program will spawn */ #define MAXNCHILD 20 /* Tag to use for the join message */ #define JOINTAG 11 int main(int argc, char* argv[]) { int ntask = 3; /* return code from pvm calls */ int info; /* my task id */ int mytid; /* my parents task id */ int myparent; /* children task id array */ int child[MAXNCHILD]; int i, mydata, buf, len, tag, tid; /* find out my task id number */ mytid = pvm_mytid(); /* find my parent's task id number */ myparent = pvm_parent(); if ((myparent < 0) && (myparent != PvmNoParent)) { pvm_perror(argv[0]); pvm_exit(); return -1; } /* Parent */ if (myparent == PvmNoParent) { /* spawn the child tasks */ ntask = pvm_spawn(argv[0], (char**)0, PvmTaskDefault, (char*)0, ntask, child); for (i = 0; i < ntask; i++) { /* recv a message from any child process */ buf = pvm_recv(-1, JOINTAG); info = pvm_bufinfo(buf, &len, &tag, &tid); /* process message */ } pvm_exit(); return 0; } /* Child */ info = pvm_initsend(PvmDataDefault); /* Create message */ info = pvm_send(myparent, JOINTAG); pvm_exit(); return 0; } |
Each process has a task id. A process dynamically creates child processes that run on other nodes. Then it receives messages that come from the children whose creation succeeded. Child processes send messages to their parent.
You can find more information at http://www.netlib.org/pvm3/book/pvm-book.html.
MPI stands for Message Passing Interface. This interface is designed for MIMD and SPMD programming. The MPI standard includes:
Point-to-point communication: send or receive in blocking or non-blocking mode
Collective operations: broadcast, barrier synchronization, scatter, gather, global reduction (operations on buffers)
Groups, contexts and communicators. A communicator defines a communication context or universe. A process group shares this communication context. A process is identified by a number – its rank – in the process group.
Process topologies
Environment management and inquiry
Profiling interface
MPI was designed for scientist and therefore defines binding for C and Fortran. For one part, the complexity of MPI is due to the support of those languages and to interoperability requirements. In that respect MPI compares to CORBA.
The MPI official site is http://www.mpi-forum.org/.
We recommend reading the MPI version 2 document, the MPI version 1.1 document and the journal of development.
Here is a short informal introduction to MPI.
MPI is made of a daemon or Windows service and of a function library that you install on every node.
Then you use an MPI command to start a process in parallel on all nodes. Here is an example of process code:
#include <stdio.h> #include ''mpi.h'' main(int argc, char** argv) { int my_rank; /* Rank of process */ int p; /* Number of processes */ int source; /* Rank of sender */ int dest = 0; /* Rank of receiver */ int tag = 50; /* Tag for messages */ char message[100]; /* Storage for the message */ MPI_Status status; /* Return status for receive */ MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); MPI_Comm_size(MPI_COMM_WORLD, &p); if (my_rank != 0) { sprintf(message, ''Greetings from process %d!'', my_rank); MPI_Send(message, strlen(message)+1, MPI_CHAR, dest, tag, MPI_COMM_WORLD); } else for (source = 1; source < p; source++) { MPI_Recv(message, 100, MPI_CHAR, source, tag, MPI_COMM_WORLD, &status); printf("%s\n", message); } |
All processes run this code. The processes with a rank > 0 send a message to the process with rank 0 (the destination). The process with rank = 0 receives the messages of all other processes. MPI_Send and MPI_Receive are typical middleware verbs. MPI also supports collective verbs. Those verbs, such as MPI_Gather and MPI-Scatter, take a root parameter and act differently if they are called from a process with rank = root.
For instance with MPI_Gather, processes with a rank different of root send a message and the process with a rank = root receives the message. You no longer need to code conditions and loops and the MPI daemon and library can optimise your request. In the same way you can specify reduction operations that can take place in intermediate nodes to achieve a higher level of parallelism.
MPI is efficient but fault-tolerance is not its strong point: if a process crashes all other processes get an error and have no choice but to end. With the LAM implementation it is possible though not easy to implement a limited form of fault tolerance. The situation is the same with MPI-2 but it requires extra coding. FT-MPI aims to address this drawback.
With FT-MPI communicators have different failure modes: The communicator can shrink when a process fails or force the creation of new processes to fill the emptied ranks. You can find interesting documents about FT-MPI (also called Harness, which stands for Heterogeneous Adaptable Reconfigurable Networked Systems) at http://icl.cs.utk.edu/harness/.
Grid environments are typically available on Unix (Solaris) and on Linux. Sometimes they also run on Windows NT.
We recommend reading first the PhD dissertation of Amin Vahdat. This document has been a great source of inspiration for us. The WebOS parent project, NOW wrapped up in 1998, officially ending the WebOS project.
WebOS introduces an Active Naming mechanism. Active Naming interposes programs behind the naming interface. This approach has several benefits compared to the existing DNS:
Support for Load balancing, migration, replication, fail over and caching
Minimization of the latency and consumed wide area bandwidth
A local Active naming program can check which servers are up, use a growing or shrinking number of servers and balance requests between the less loaded servers.
Active naming provides a framework for binding names to programs and for chains of programs to cooperate in translating a name to the data that name represents. Active Names are strings that take a format namespace/name. The namespace identifies a Namespace program that knows how to translate the name field of an Active Name into the resource it represents. To find the resource location, the Namespace program typically calls a hierarchy of name resolvers.
Condor is a specialized workload management system for compute-intensive jobs developed by the University of Wisconsin.
"The goal of the Condor Project is to develop, implement, deploy, and evaluate mechanisms and policies that support High Throughput Computing (HTC) on large collections of distributively owned computing resources."
Condor team introduced a distinction between High Performance Computing (HPC) and High Throughput Computing (HTC). The key to HTC is effective management and exploitation of all available computing resources. The main challenge a typical HTC environment faces is how to maximize the amount of resources accessible to its customers and not to provide a high performance.
As a workload management system, Condor only knows jobs. This allows setting Condor to only use idle machines and to suspend jobs when the machine is used for another task. With parallel programs using PVM or MPI the participating machines must be dedicated to computation or at least have spare resources.
You can download Condor on http://www.cs.wisc.edu/condor/downloads/.
Condor runs on Windows NT.
PVM is also a product developed by the Oak Ridge National Laboratory that you can download at http://www.csm.ornl.gov/pvm/.
Adam Ferrari has written a JPVM package that you can download at http://www.cs.virginia.edu/jpvm/src/jpvm.zip. It is not interoperable with PVM but it is portable (100% Java) and it provides a similar API with a better thread support.
MPICH is a product implementing the MPI protocol and developed by Argonne National Laboratory.
MPICH runs on Unix, Linux and Windows. The Windows version supports Visual C++ and Visual Fortran as well as gcc. MPICH is free and you can download its sources.
On Unix and Linux MPICH can run on top of Globus (MPICH-G2).
You can download MPICH at http://www-unix.mcs.anl.gov/mpi/mpich/download.html.
The site contains very interesting documents on its design. You can check http://www-unix.mcs.anl.gov/mpi/mpich/papers/mpicharticle/paper.html#Node0 and http://www-unix.mcs.anl.gov/mpi/mpich/workingnote/adi2impl/note.html#Node0.
LAM stands for Local Area Multi-computer and also implements MPI.
LAM runs on Unix and Linux. Like MPICH LAM is free and you can download its sources.
Compared to MPICH,
LAM has been integrated in fewer products and doesn’t work on Windows
LAM used to be faster
LAM probably supports more MPI-2 functions such as dynamic process spawning
LAM implements an Interoperable Message Passing Interface (IMPI). A paper called IMPI Extensions to LAM/MPI presents its design. You can download the paper at http://www.lam-mpi.org/papers/mpidc2000/
You can download LAM at http://www.lam-mpi.org/download/.
Globus is the most important project in Grid computing and the Globus toolkit is the de facto standard for major protocols and services. The Globus toolkit is the most comprehensive implementation of the Grid concept. Globus site is http://www.globus.org/.
Globus toolkit is big and complex. For that reason it is only available on Linux and on some Unixes (Solaris, AIX, IRIX and Tru64). Globus toolkit has three pillars:
Resource management. Resource Management involves the allocation and management of Grid resources. It includes components like GRAM, DUROC, and GASS.
Information Services. Information Services provide information about Grid resources. This area includes MDS, which provides the GIIS and GRIS components.
Data Management. Data Management involves the ability to access and manage data in a Grid environment. This includes components such as GridFTP, which is used to move files between Grid-enabled storage systems.
Once you have downloaded and installed the Globus toolkit, you can also install optional components:
MPICH-G2, an MPI v1.1 implementation
CoG Kits that allow using the Globus toolkits in different environments and languages (for instance Java)
The Globus site contains a huge amount of documentation and the toolkit itself is an open architecture, open source software toolkit.
The Open Grid Services Architecture (OGSA) is a proposed evolution of the current Globus Toolkit towards a Grid system architecture based on an integration of Grid and Web services concepts and technologies. It could be called Globus toolkit 3.0.
National Science Foundation uses the Globus toolkit (as well as Condor) in its middleware initiative NMI-R1. You can download that package at http://www.nsf-middleware.org/.
Acronym | Meaning |
|---|---|
GRAM | Globus Resource Allocation Manager |
DUROC | Dynamically-Updated Request Online Coallocator |
GASS | Global Access to Secondary Storage |
GIIS | Grid Index Information Service |
GRIS | Grid Resource Information Service |
MDS | Monitoring and Discovery Service |
GPT | Grid Packaging Technology |
GSI | Grid Security infrastructure. GSI builds on TLS (SSL) |
GRIP | Grid Resource Information Protocol. Based on LDAP |
GRRP | Grid Resource Registration Protocol |
Legion aims to provide a single, coherent virtual machine addressing scalability, programming ease, fault tolerance, security and site autonomy within a reflective, object-based meta-system.
It is an ambitious project: Legion could consist of millions of hosts.
Organizations that provide a set of hosts can keep control of their resources.
Legion must be extensible, scalable and easy to use. It must hide machine boundaries.
Legion must support multiple languages and even legacy code.
Perhaps the most interesting part of the Legion effort is the Mentat language. The name is a bit surprising. You perhaps remember that in Dune computers were forbidden by a butlerian Jihad and some humans, the mentats were trained to replace them.
Mentat is an object-oriented, control-parallel programming system designed to address three problems:
The difficulty of writing parallel programs
The difficulty to achieve portability of those programs
The difficulty of achieving portability of those programs
Mentat has two primary components:
The Mentat programming language (MPL), based on C++
The Mentat runtime system that has been ported to massively-parallel procesors and some Unix machines
Mentat has a couple of competitors:
HPC++, High Performance C++ that you can find at http://www.extreme.indiana.edu/hpc++/.
HPF, High Performance Fortran. Though Fortran is not the most modern language, it is the language of choice for parallel programs. You can find numerous implementations at http://dacnet.rice.edu/Depts/CRPC/HPFF/compilers/index.cfm.
Legion site is http://legion.virginia.edu.
The Legion software is currently available to qualified educational, research, and commercial customers. You need to send a mail to get a copy. You can also need to contact Avaki, the corporate distributor of Legion software.
Low-level APIs such as MPI have several drawbacks:
They are not fault-tolerant
They require writing and testing technical code
They primarily support Fortran and C
They allow using distributed resources but they don’t help for using application libraries
Many generic modules are available. You can find lists at http://www.netlib.org/master/expanded_liblist.html, http://rib.cs.utk.edu/cgi-bin/catalog.pl?rh=222, http://www.nhse.org/software.html and http://www.netlib.org/utk/people/JackDongarra/projects.htm.
NetSolve was designed to provide a fast, efficient, easy-to-use system to effectively solve large computational problems using such modules. Issues such as Networking, Heterogeneity, Portability, Numerical Computing, Fault Tolerance and Load Balancing are dealt with by NetSolve.
NetSolve provides a simple client API in Fortran, C, Mathlab and Mathematica. A new Java flavor could be available sometime in the future. The simplest function has this prototype:
int netsl(char *problem_name, ... < argument list > ...)
where problem_name is a module supported by the invoked NetSolve environment.
When you call this function, NetSolve analyzes your arguments (typically the size of your input matrices), the available instances of the module and how busy are their hosts. Then NetSolve distributes your work to the most appropriate instance. In case of failure NetSolve can retry the computation.
NetSolve supports parallel processing. However its function is to allow distributed computing.
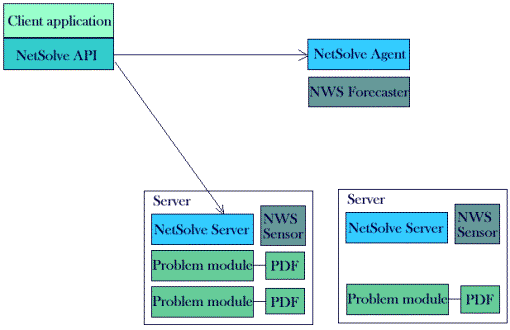
NetSolve has three components:
The NetSolve API
The NetSolve Agent
The NetSolve Server
The NetSolve agent maintains a database of NetSolve servers along with their capabilities (hardware performance and allocated software). It uses an NWS Forecaster to get the dynamic characteristics of the NetSolve servers (available CPU and network performance). NWS is a very interesting system that we describe here. It is also used by Globus and Legion. For the understanding of this diagram it is enough to say that the NWS Forecaster uses measurements made by the NWS Sensors.
When we call a function of the NetSolve API,
The NetSolve API contacts the agent for a list of capable servers
The NetSolve API contacts a server and sends the input parameters
The NetSolve server runs the appropriate module
The NetSolve server returns the output parameters
The problem description file (PDF) is the mechanism through which NetSolve enables modules for the user. It gives the processing cost of the module. Using the information returned by the NWS Forecaster, the input parameters and the processing cost of the module the NetSolve Agent can select the most suitable server.
For more information or to download NetSolve, look at http://icl.cs.utk.edu/netsolve/.
NetSolve can use the Internet Backplane Protocol (IBP).
IBP has two kinds of components, IBP clients and IBP servers (depots).
Depots provide storage space whereas clients can read or append data.
In the simplest scenario the NetSolve client allocates a byte array and move its data on a depot, then it uses the NetSolve API to send a request with the location of its IBP datastream. Then the module can retrieve the data from the depot. IBP also allows moving the byte array close to the NetSolve server. In a third scenario the client requires a computation that involve two modules and a depot is used to store the intermediate result.
You can find documentation about IBP at http://loci.cs.utk.edu/ibp/documents/.
You can download IBP from http://loci.cs.utk.edu/ibp/downloads/.
In the future the NetSolve API could be replaced by a standard GridRPC API. For more information you can look at http://www.netlib.org/netlib/utk/people/JackDongarra/PAPERS/grpc.pdf.
Netsolve Web site requires that we add the following text when referencing NetSolve in a publication:
@TECHREPORT{nug,
AUTHOR = {Arnold, D. and Agrawal, S. and Blackford, S. and
Dongarra, J. and Miller, M. and Seymour, K. and
Sagi, K. and Shi, Z. and Vadhiyar, S.},
TITLE = {{U}sers' {G}uide to {N}et{S}olve {V}1.4.1},
INSTITUTION = {University of Tennessee},
YEAR = {2002},
TYPE = {{I}nnovative {C}omputing {D}ept. {T}echnical {R}eport},
MONTH = {June},
ADDRESS = {Knoxville, TN},
NUMBER = {ICL-UT-02-05} }
The PageBox Grid must be easy to install and must not require a porting effort.
The PageBox Grid doesn't aim to compete with low-level, high performance environments.
The Pagebox Grid should provide high throughput rather than high performance. Compute-intensive jobs are not necessarily its main application.
The PageBox Grid should rather allow retrieving data, performing searches, maintenance and monitoring tasks on large sets of computers in parallel. A typical PageBox grid requestor doesn't ask the grid to perform a computation but rather to return information scattered on the grid.
The PageBox Grid can also be used to maintain memory caches in sync.
The PageBox Grid is used in interactive mode. A computation is issued either when a user makes a request on an HTML form or when a Web service is invoked.
The PageBox Grid should be available in Java and C#.
Using pre-compiled code running on Virtual machines has several advantages:
No interoperability problem.
Security. Pre-compiled code can be signed. The host can grant permissions to the code depending on its trust in the code source.
No portability problem. The performance that you get using C or Fortran comes at a high porting cost.
The PageBox Grid uses SOAP, SMTP and UDP.
The C# version of the PageBox Grid uses the ASP.NET SOAP.
The Java version of the PageBox Grid uses JAX-RPC.
With PageBox, a Web Service provider can also provide a Control, which is a GUI snippet that knows how to call the Web service. The Web service user includes this control in its portal or WebTop. Because the Web Service provider publishes a new version of the control when it updates its Web service, the Web service user has nothing to do when the Web service changes.
Because PageBox allows distributing any kind of Web application it allows distributing the Web services onto a large set of locations. If the provider deploys its Web services on a large but variable number of computers, it needs a way to route requests:
Depending on the data. A server A can manage the accounts between 1 and 9999, a server B the accounts between 10000 and 19999 and so on. With a data dependent routing Web services requests for an account 12000 will be automatically sent to server B.
Depending on the location. With a location dependent routing Web service requests from one client will be sent to the closest (lowest network latency) server.
With load balancing and fault tolerance. Requests should be balanced between the active servers depending on their load.
Let's take an example of Web service proxy generated by wsdl.exe in an ASP.NET environment. The coding is quite similar in Java:
[System.Web.Services.WebServiceBindingAttribute(Name="MyService", Namespace="MyNamespace")] public class MyService : System.Web.Services.Protocols.SoapHttpClientProtocol { public MyService() { this.Url = MyActiveNaming(); } ... } |
The Web Service provider sets the Web service URL with an MyActiveNaming method.
MyActiveNaming uses the Active Naming API to retrieve available Web service instances and to select the most appropriate one.
The Active Naming API is implemented in an ActiveNaming Web service defined in the PageBox namespace and hosted in the PageBox Web application.
This Web service provides a method with a signature:
ActiveNaming.Candidate[] GetCandidate(String repository_URL, String WebService_archive, String WebService_name);
Where
repository_URL is the repository where the Web service has been published
WebService_archive is the name of the archive where the Web service was packaged
WebService_name is the Web service name
GetCandidate returns an array of Candidate object. The Candidate class has this definition:
public class Candidate { public String URL; public String keyRange; } |
URL is the URL of the PageBox that deployed the Web service.
The implementer uses it
To compute the Web service URL
To get the Web service IP address and find the closest neighbour of the client
The ActiveNaming Web service provides another method, SetKeyRange:
void SetKeyRange(String keyRange);
keyRange is typically used to set a key range (data depending) but it can be any data that the implementer can need to route requests to the most appropriate instance.
The ActiveNaming service is implemented in the same way as the Query Web service.
GetCandidate uses the RepoQuery Web service of repository_URL to retrieve the list of the PageBox subscribing to WebService_archive. Then it calls a method GetKeyRange of the ActiveNaming Web service for each PageBox in the list to retrieve the candidate keyRange.
If the repository doesn't answer, GetCandidate uses a cached list, which is the list returned by the previous successful RepoQuery invocation. If a PageBox doesn't answer to the GetKeyRange request, the candidate instance is considered as inactive and removed from the list.
Actually GetCandidate doesn't poll the candidate PageBoxes each time it is invoked. It caches the list in memory.
The API is inspired by MPI.
The PageBox Grid API methods are defined in a Grid class defined in a PageBoxGrid namespace.
Our first idea was to define communicator, process and process group like this:
A communicator is made of the subscribers to a repository; it is what we call a PageBox constellation.
A process is a deployed instance of a Web Application.
A process group is made of all instances of a Web application deployed from a single repository. Many process groups can coexist in the same communicator because a process group represents a published Web application.
Because we are in multithreaded environment we chose to represent a process by a Grid object.
The Grid constructor takes a communicator parameter. A communicator is uniquely defined by (repository_URL, communicator).
Each Grid instance has a unique sequence number in its Web application instance, itself uniquely defined by its IP address, port and mail address. A process is uniquely defined by (repository, communicator, IP address, port, mail_address, sequence number).
We actually expect this programming style:
... import PageBox.Grid; class Participant extends Thread { private Grid myGrid; public Participant() { start(); } public void run() { myGrid = new Grid(...); ... }} |
You must instantiate Grid in the created thread.
The following table summarizes the previous discussion.
MPI | PageBox |
|---|---|
Communicator | Constellation / repository + communicator parameter |
Process | Grid object |
Process group | Set of the processes in a communicator |
A process retrieves the base URL of the other processes in its group using the Query Web service of PageBox. It can call the Web services offered by the other Web application instances. The process knows these Web Service URIs because:
It knows their process base URL
The other Web application instances are just its clones. Therefore their Web Services are the same as its Web Services
This mechanism is useful
To initialize the processes
To distribute coarse grain computations in Master/Worker mode
SOAP has two weaknesses:
SOAP uses XML over HTTP. This fact has an impact in term of message size and parsing cost. SOAP is only effective if the invoked code processing costs much more than the request parsing and response formatting.
SOAP is unicast
The core of the PageBox Grid API is designed to address these limitations.
The typical MPI verb is MPI_SEND. It has this signature:
MPI_SEND(buffer, count, datatype, dest, tag, comm);
where buffer is the initial address of the send buffer,
count is the number of elements in the send buffer,
datatype is the type of each element in the send buffer,
dest is the rank of the target process in its process group,
comm is the communicator.
You call the PageBox Grid API with:
Grid.Send(object, dest, transport_mode);
Dest is the rank of the target Web application in the list returned by the Query Web service.
Transport mode can be Transport.SMTP or Transport.UDP.
Send serializes the object into a binary stream and sends it with the defined transport mode, then it returns (non-blocking mode).
In UDP mode the API doesn't check for transmission loss.
Why an MPI-like and not an RPC API? Object RPC are mainly useful to facilitate object design. The support of objects as parameters gives the same benefits in term of programming convenience and maintainability as object RPC. For our needs object RPCs have two drawbacks:
|
In case of PageBox Grids processes are created by Repositories and PageBoxes.
In a Web application using VM managed code:
The creation of OS processes and even of threads or objects is expensive
Resource freeing is actually performed by the Garbage collector
For these reasons:
The PageBox Grid API doesn’t create OS processes
Process threads and objects are typically created at the instantiation of the Web Application. They last up to the Web server shutdown. Therefore the process list changes (processes enter and leave the communicator) and cannot be static like in MPI.
All processes can act concurrently as master and slave process. The master processes are event handlers that send messages to other processes. Slave processes process and acknowledge master messages.
Signature:
int Send(Object o, int dest, int transport_mode);
where
o is the object to send
dest is the rank of the target Web application in the list returned by the Query Web service
transport_mode is either SMTP or UDP
Send return -1 in case of failure.
Implementation note:
Send actually serializes an object containing the user object and the group id.
In case there is no message available, Receive waits up to a time defined in the Grid constructor for a message.
Signature:
Grid.Message Receive(int transport_mode);
Receive returns a Message structure or null in case of failure.
Grid.Message has this definition:
public structure Message {Object recv;int from;int transport_mode;}
where
recv is the received object
from is the rank of the origin Web application in the list returned by the Query Web service
transport_mode is either Transport.SMTP or Transport.UDP
In case there is no message available, ReceiveNonBlock returns null.
Signature:
Grid.Message ReceiveNonBlock(int transport_mode);
Receive returns a Message structure or null in case of failure.
Grid.Message has this definition:
public structure Message {Object recv;int from;int transport_mode;}
where
recv is the received object
from is the rank of the origin Web application in the list returned by the Query Web service
transport_mode is either Transport.SMTP or Transport.UDP
Scatter sends an object to all other processes in the group.
Signature:
int[] Scatter(Object[] os, int transport_mode);
where
os is the array of objects to send
transport_mode is either Transport.SMTP or Transport.UDP
If there are less input objects than processes in the group, Scatter distributes the objects to the first processes.
If there are more input objects than processes in the group, Scatter sends more than one object per process.
Scatter returns an array of integers whose size is the number of destinations.
For a destination the array entry contains:
-1 if the send failed
The number of messages sent to this destination
Here is the Scatter pseudo code:
int Scatter(Object[] os, int transport_mode) { int first = 0; while(true) { for (int i = 0; (i < dest.Length) && (os.Length > i + first); ++i) Send(os[i + first], i, transport_mode); if (os.Length == i + first) break; first += dest.Length;} ... |
Gather waits for a set of objects coming from other processes.
Signature:
Grid.Message[] Gather(int[] dests, int transport_mode);
dests is typically an array returned by a former scatter. Its size is the number of destinations.
When an entry in dest contains 0 or –1, no message is expected.
Otherwise Gather receives the number of messages defined in the entry.
Gather returns an array of Message structures even if the timeout expires.
The user can check the returned array to check if it is the case.
The user can also check the type of the returned objects.
Subscribe registers a message handler. A message handler is an alternative to the use of the Receive and ReceiveNonBlock verbs.
Signature:
void Subscribe(GridCallback gc);
The message handler must implement a GridCallback interface defined like this:
public interface GridCallback { void Notify(Transport transport_mode, int from, object o); } |
where
transport_mode is either Transport.SMTP or Transport.UDP
from is the rank of the origin Web application
o is the received object
Notes:
Notify is called each time a message is received. Therefore Receive and ReceiveNonBlock return null when a message handler is defined
The message handler is called in the listener threads
Scatter should use UDP multicast if applicable.
The Grid objects are the facades to the core implementation typically managed by a singleton.
The implementation typically involves:
A UDP listener thread
A POP3 listener thread
A ping thread. The process list is likely to change, Web servers going down and up all the time. A given rank can also point on different Web Applications depending on the time.
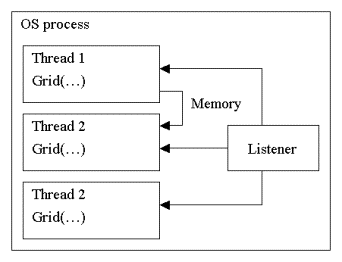
When the destination is in the same OS process, the reference to the message object is just queued on the target Grid object (memory communication).
With transport modes such as UDP and SMTP we cannot control the order of arrival. Therefore the listener:
Reads the message and unserializes the object
Analyzes the object destination
Queues the object on the target Grid object
We can compare this model with the modes supported by MPICH:
Eager. In this mode, data is sent to the destination immediately. It is the mode that we use with UDP and SMTP transport.
Rendezvous. In this mode, the destination is only notified of the message arrival. The destination sends the source a request for the data and provides a way for the sender to return the data.
Get. In this mode, data is read directly by the receiver. It is the mode that we use with memory communication.
We move to a layered, modular architecture.
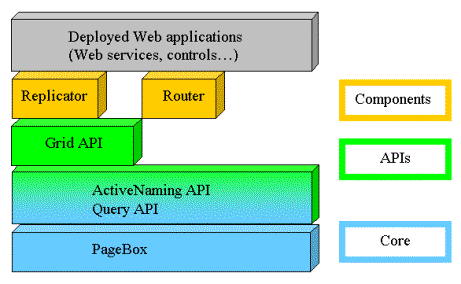
At the bottom, the PageBox core installs the published Web applications.
The Query API allows Web application instances to find out their clones deployed by the same repository.
The ActiveNaming API uses the Query API to retrieve the Web service URLs and routing information.
The Grid API uses the ActiveNaming API to implement communicators and message passing.
The Router component uses the ActiveNaming. It supports:
Location depending routing. Location dependent routing aims to route requests to the closest Web service instance. If there is a Web service instance in the same IP address range as the requestor then this instance is selected
Data dependent routing. Data dependent routing selects the Web service instance able to process the request using the routing information (typically key range) published by the Web service instances
Load balancing
The Replicator component allows keeping in sync across Web applications cached information such as Session data. The Replicator component uses the Grid API.
Active Naming allows implementing scenario like this:
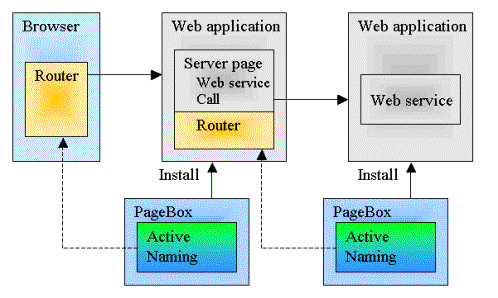
The browser page uses the Router wrapped in an applet or ActiveX control.
The client-based Router uses information from the PageBox Active Naming to balance requests, select the closest Web Application instance and support fault tolerance.
The Server page calls a Web Service. It uses the Router to retrieve the Web Service URL.
The server-based Router uses information from the PageBox Active Naming to balance requests, to select the closest Web Application instance or a Web application that has the data and to support fault tolerance
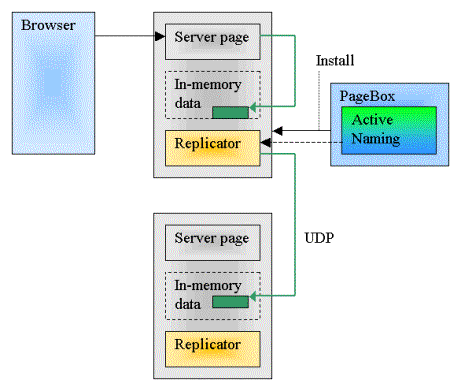
When a server page modifies the cache on one Web application instance, it invokes a Replicator object.
The Replicator uses the PageBox Grid API to scatter the cache change to the other Replicator instances.
The remote Replicator instances update their cache.
Because all Web server instances have the same cache state, you can balance requests between Web server instances.
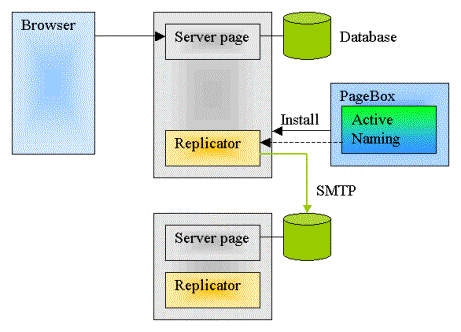
When a server page updates the database, it invokes a Replicator object. The Replicator uses the PageBox Grid API to scatter the cache change to the other Replicator instances. The remote Replicator instances update their database instances.
Updates are guaranteed. The Replicator sends update message to an SMTP server. If the SMTP is not running it can fall back to another SMTP server. If the target Web application is not running when the update message is sent, when it starts again it first reads its mails and processes its update requests.
On the long term, the combination of the PageBox deployment and of the Grid for data and processing distribution should allow a Web infrastructure to act as a brain:
Its Web application instances hosted on inexpensive computers would be less powerful and reliable than super servers just like a neuron is less powerful than any computer.
However because each instance knows many ways to serve the user the aggregated power and reliability of the Web brain should far exceed the performance of any computer and hide network failures.
Java PHP .NET
Reservation Controls Java controls
Polaris Grid Coordinator Grid V2
Distribution Installation NWS
Contact:support@pagebox.net
©2001-2004 Alexis Grandemange
Last modified