| PageBox |
| Support | Map |
|
|
|
|
|
|
|
A practical solution for the deployment of Java Server PagesSometimes it is worthwhile to revisit your former work. It certainly was for me in the following case, which resulted in the core concept of using presentation as a commodity to be deployed according to network configuration.
The original project assignment was to reduce operating costs of a large banking agency network. How could this be achieved with a network of 23000 personal computers (PC) scattered over 2000 sites connected by frame relay with a guaranteed bandwidth of 32Kb/s? We selected an Intranet solution that radically reduced PC client/server applications to a single local program, the browser. To reduce bandwidth needs we chose to deploy a Web Server per site with only 3 tasks – to handle presentation, to maintain reference data and to invoke central system applications. This Intranet design saved money by reducing the number of machines to operate from 23000 to 2000 and by allowing them to be operated with a browser.
With Java and J2EE, we can implement this concept, which I believe to be still valuable to reduce the load of central farms – and because fast local loop is not always available. My goal however is to more specifically show how we can do it better. The aforementioned approach didn’t support Web Servers update on the fly and we had to contend with central systems synchronization. The solution I present here addresses these issues by allowing Web Servers to download their presentation like browsers download applets.
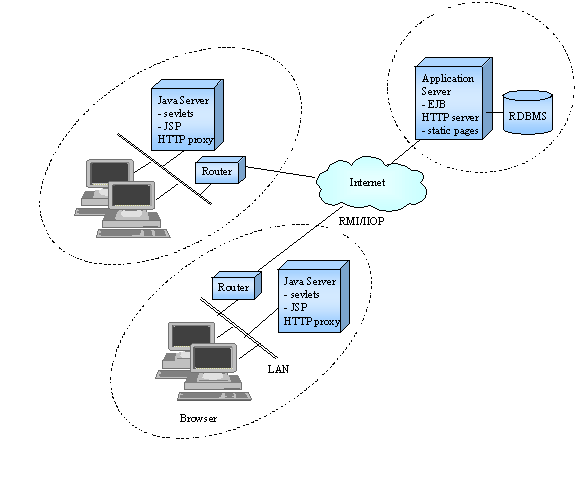
Figure 1 illustrates a possible organization. Let’s summarize what we would need: 1. Inexpensive Java servers, able to host Java Server Pages and servlets 2. An API allowing them to invoke central system applications 3. A simple way to download a presumably large number of Java servers from any number of central repositories.
Figure 1: Topology The first two requirements can be fulfilled by off the shelf products: The local Java server has only to address the 3 purposes listed above · Generate presentation, · Invoke central applications · Maintain reference data At least two Open Source Products meet these needs: Tomcat (http://jakarta.apache.org/downloads/binindex.html) and Resin (http://www.caucho.com/download/index.xtp). Enterprise JavaBeans (EJB), Remote Method Invocation (RMI) or Java Messaging Service (JMS) can be used as the API to connect to central systems.
The last point, presentation downloading, implies development. This requires more explanation and thoughts and is the core of the article. Presentation downloading relies on a Java class loader and leverages on JSP and servlets specifications, which I present first. StandardThe Java Servlet Specification v2.2 defines a Web Application as a collection of HTML pages, servlets and classes, which exist as a structured hierarchy of directories. The root of this hierarchy is the document root for serving files like images or html files. If your Java server waits for HTTP requests on www.iamakishirofan.com, and if you defined your Web Application as gunnm, your users will be able to invoke zalem.html, stored at the root with the URL: www.iamakishirofan.com/gunnm/zalem.html.
A directory WEB-INF contains a web.xml file, which describes, among miscellaneous things, Servlet and JSP definitions, initialization parameters, mapping to URL and security constraints. It can also contain a classes subdirectory where classes, servlets, taglibs, JSP invoked beans, compiled JSP… are stored. A Web Application should be packaged in a .war file, which is the jar archive of the hierarchy.
This packaging is convenient as it gathers all related components in a single delivery. It has another important property: all servlets and JSPs of a .war are served the same ServletContext, which is different from the ServletContext of other packages. Servlets and JSPs can use this ServletContext to access war data like resources and initialization parameters, or to store and retrieve application-wide attributes.
The servlet container loads and instantiates servlets. It initializes them before their first use by calling their init() method with an object implementing the ServletConfig interface, which provides access to servlet-specific data. When it decides to unload a servlet, it invokes the servlet destroy() method and unreferences it. Each time the container has to route a request to a servlet, it invokes its service() method.
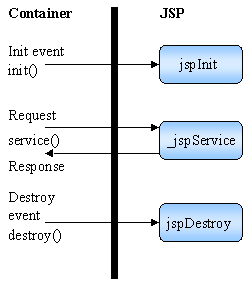
A compiled JSP is a servlet, even if it does not extend HttpServlet or GenericServlet as a normal servlet but another class, which is Application Server dependent. In case of Resin, it is com.caucho.jsp.JavaPage and in case of Tomcat, org.apache.jasper.runtime.HttpJspBase. As you can see, compiled JSP are no longer portable, even if there are only minor differences: The specification requires a JSP to implement a standard HttpJspPage interface. A JSP indirectly handles container requests as depicted on Figure 2.
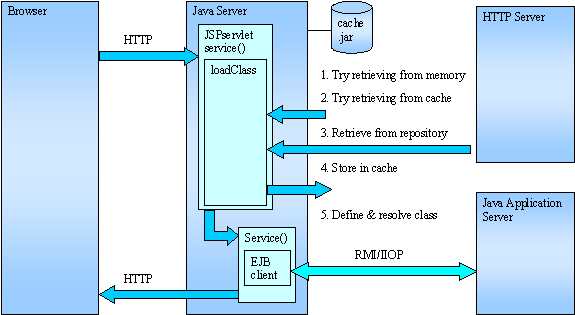
Figure 2: JSP contract A compiled JSP implements a _jspService() method and, optionally, a jspInit() and a jspDestroy() method. The specification implies that, for instance, when the container invokes Servlet.init(), jspInit() is invoked somewhere in the implementation of the JSP base class. I present you the Tomcat implementation on Listing 1. All Java servers I tested have similar code. ChoicesComing back to our requirement, you can see the solution I want to implement involves four participant types: § Browsers, which submit HTTP requests. § Java Servers, which process presentation and download the JSPs and servlets from a repository. § Repositories, themselves. I only require the repository to be accessed with an URL. Therefore suitable repositories list includes HTTP servers as depicted on Figure 3 and FTP servers. § Java Application servers, which process EJB requests.
I only need to implement in the Java Server a piece of code able to retrieve transparently JSPs and servlets from a central point, to cache them and to support remote update. The solution depicted on Figure 3 is just common sense: I define a special servlet, JSPservlet, which I package in a .war file to handle all requests targeting its Web Application. This servlet is responsible for loading target JSP and servlets and to forward them requests. To minimize data transfers I handle only archives (.jar) files and I cache downloaded archives, not only in memory but also on disk, to survive a scheduled shutdown or a crash.
Figure 3: Solution To simplify the development, I don’t handle JSP compilation. It does not mean the solution doesn’t support JSPs, only that they have to be precompiled, which is not a real drawback. Compiling JSP is the only safe way to be sure a JSP can compile and I prefer to avoid downloading failing code. I also don’t support Single thread servlets which guarantee that only one thread at a time will execute through a given servlet instance’s service() method.. The support of this feature would require instantiating a new target servlet when already created target servlets are processing a request. It would add complexity to the logic and would have an adverse impact on scalability.
Listing 2 shows the deployment descriptor (web.xml) of the JSPservlet application. You can see how to define that. JSPservlet must handle all requests targeting the application. You specify in <servlet-mapping> <url-pattern>/</url-pattern> and not <url-pattern>*</url-pattern> as you could expect. Note that I use <init-param> to set every machine dependent parameter. Deployers can then modify them to accommodate different installation and Operating System requirements. cachePath is the directory where downloaded jars are locally stored and remoteLocations indicates a property file where remote locations are defined. For instance, if a jar file named myjar must be downloaded from an HTTP server www.mysite.com, remoteLocations will contain an entry myjar=HTTP://www.mysite.com. Implementation
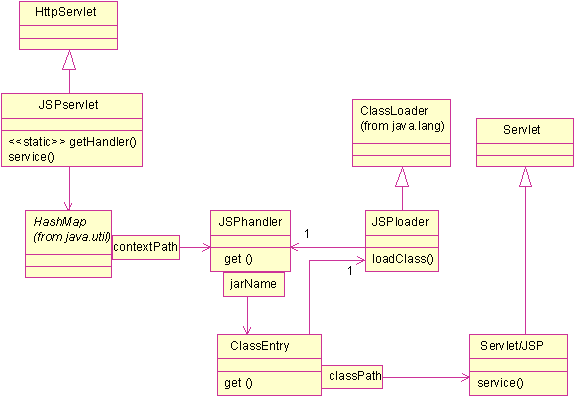
Figure 4: class diagram Let’s look at the class diagram figure 4. You see the aforementioned JSPservlet, which relies on a JSPhandlers HashMap of JSPhandler. There is a JSPhandler instance per application, which reads parameters and maintains ClassEntry objects, one per archive. ClassEntry maintains a target servlets cache and a JSPloader instance. JSPloader is the class loader itself and maintains a class cache. It is also responsible for saving locally downloaded archives.
We can now see how the solution works. The Java Server calls JSPservlet service(). To know which servlet is requested, JSPservlet.service() uses the request object. It first find the appropriate JSPhandler with getHandler() passing the application name it retrieves using the request getContextPath(). Then it gets a reference on the target with JSPhandler.get(), passing the path to the target returned by the request getPathInfo(). Eventually it uses this reference to invoke the target object service() method. As you can see on Listing 3, that’s all for JSPservlet.
Listing 4 shows the implementation of JSPhandler. Its constructor retrieves parameter values from web.xml using ServletConfig.getInitParameter() and restores remote location properties from their persisted state. I chose to use the first part of the path as the archive name and the remaining part as the class name. Given a URL www.iamakishirofan.com/gunnm/gally/nano/machine, if the application server is configured with the JSPservlet application on gunnm, ContextPath will be gunnm, the archive will be gally and the servlet path in the archive will be nano/machine.class. This may seem a bit rough compared to the Web Application flexible mapping but it is simpler to administrate and to implement. So JSPhandler.get() parses the pathInfo string and uses the archive part to find the corresponding ClassEntry in classEntries HashMap. It creates a ClassEntry if the search fails and invokes its get() method.
Now we can look at ClassEntry implementation in Listing 5. Its constructor creates a JSPloader. Its get() method first try to get the target servlet from its instance cache, servletObjects. No matter how many times a servlet is invoked, a single object is used and reused. If the object does not yet exist, it uses JSPloader to retrieve its Class, invokes Class.newInstance() to instantiate it and Servlet.init() to initialize it. It is extremely close to Java servers’ implementations. Class loaderBefore diving into the last and most complicated piece of code, JSPloader in Listing 6, let’s recap what a class loader is and what our class loader is intended to do. A class loader is an object responsible for loading classes. Given the class name, it can generate or load its binary code. A class loader inherits from ClassLoader, which provides methods you can override, the most flexible being loadClass. ClassLoader also implements service methods, defineClass, which converts the binary code in Java class and resolveClass, which links it. JSPloader must load classes from jar files located either in cachePath or at a URL. Coming back to our example, it retrieves the archive either from the local cache in cachePath/gally.jar or download it from a URL, which is the value of a gally property, persisted in remoteLocations. In addition, when JSPloader downloads an archive, it must save this archive in its local cache, cachePath/gally.jar.
I prefer loading classes in JSPloader constructor to minimize disk and network access duration and numbers. Another advantage is the forced loading can be performed outside peak hours by an administration JSP. JSPloader will then deliver a better response time, classes being already in memory. I found the memory use – same order of magnitude as the size of downloaded archive – was not a showstopper. Note that I link a class only when requested and ClassEntry instantiates objects only once, when they are first requested.
JSPloader constructor tries downloading the archive from local cache with loadClassDataFS() and then from its remote location with loadClassDataURL(). Both methods build a JarInputStream from an input stream, loadClassDataFS() gets from a FileInputStream and loadClassDataURL gets from a URL.openStream(). The JarInputStream handling being then the same, I implemented it in a parseStream method.
parseStream loops around JarInputStream.getNextJarEntry(), which reads the next JAR file entry and positions the stream at the beginning of the data. So once parseStream has a JAR entry it gets its name with JarEntry.getName() and uses a BufferedInputStream to read it. Then it converts it to a class with ClassLoader.defineClass and stores it in a classes memory cache. When it has to store locally a remotely downloaded archive, it uses a JarOutputStream and each time it has read an entry, it rewrites it using JarOutputStream.putNextEntry() and JarOutputStream.write().
loadClass is invoked with two arguments, the name of the class and a boolean, resolve indicating if the class must be linked or not. Here I use passive mode on purpose. Who invokes loadClass()? It depends. When ClassEntry invokes loadClass with only the class name, no magic happens. ClassLoader implements a loadClass(name) method, which invokes loadClass(name, false). But the loaded class is associated with a JSPloader instance, which becomes the current class loader. If the loaded class uses another class the Java Virtual Machine (JVM) will invoke JSPloader.loadClass for load it. It is the reason JSPloader.loadClass delegates class loading for the classes it does not find in its classes cache to the system class loader and to its parent class loader through its loadForward method. It delegates also in two interesting cases. If the class name starts with “java.”, ClassLoader refuses creating it for security reason. So I prefer not even try. The other case is “javax.servlet.Servlet”. ClassEntry casts the target object it creates in Serlet. As I said every class is associated with a class loader instance. In fact the JVM maintains the uniqueness of (class_name, class_loader_object) and not of class_name alone. So a cast of an object of class A loaded by class_loader_object1 to the same class loaded by class_loader_object2 fails. Therefore I check javax.servlet.Servlet to not risk loading it from your archive. ConsiderationsThe order of search has an obvious security impact. I preferred trying first the classes memory cache for speed and flexibility: I really depend on Java server JDK only for Java. I can download anything else, including the EJB, JMS or RMI library code but it has a security impact. If you don’t trust your remote location, it is safer searching locally first.
My code is reasonably close to a JDK 1.1 one: you only have to replace HashMap by Hashtable and JarInputStream by ZipInputStream to run it with JDK 1.1. If local caching and JDK 1.1 have no value for you, you can consider URLClassLoader as an alternative to JSPloader. However it is not really optimized for a server side use and you should prefer the compatible NetworkClassLoader of Harish Prabandham, provided in Tomcat. Its design is similar to JSPloader but instead caching defined classes, it caches class data.
Due to lack of space, I cannot describe how to handle images, require updates from a browser, though the value of the solution stands also in its ability to both support Web applications without restrictions and allow Java Server remote update. I also cannot explain how to host downloaded classes like applets. The complete solution you can download ???? AG – where you want ???? addresses these points. ConclusionThrough the class loader comprehensive mechanism, it is simple to write a tool able to download servlets and JSP from a remote location. It is even relatively easy to make it portable though Java servers are probably the most hostile environments as they are making themselves an intensive use of class loaders.
The idea has probably a value for Corporate Intranets and Business to Business. Assume company B wants to provide access to its Web Application to company A, which maintains a Java server. A has simply to configure its server to automatically download the code from B and enjoys reduced communication bills and better response time. It is a win-win situation, as B doesn’t have to process presentation. Suppose now A has many partners. As each downloaded archive is processed by a different class loader instance, they can use the same class names without collision. If A uses a different web application for each partner, they will not share the same context. And A partners don’t even have to be aware about A Java server host and Operating System. But its real potential can be elsewhere. Assume we define a standard describing how to require a download and from where – for instance with XML over HTTP, then even ISPs could host pages. Presentation would become a commodity like routing or name service.
Installation
Constellations
Versions
Demo
Contact:support@pagebox.net |