| PageBox |
| Support | Map |
|
|
|
|
|
|
|
|
PageBox Coordinator
This document has a pre-requisite you should read before: the PageBox Control document.
The Coordinator supports cross-control interactions for Web Application controls.
It aims to support the most common needs:
Heap management
Event management
Atomic transactions
The Coordinator is a set of low-weight components designed to address Web Application control needs but it doesn’t use Web application objects. Therefore it can be used in other kinds of applications.
The Coordinator is packaged with the PageBox Grid API. The Grid API can be used by any kind of components and is actually designed to allow Web applications to communicate. This flexibility comes with a cost in term of infrastructure (repository, PageBoxes), configuration and programming. The Coordinator is a simpler environment limited to communications inside a single address space.
A Coordinator user is identified by its ID.
A Coordinator user can subscribe to events triggered by another user. The subscription creates a channel identified by its source ID, its destination ID and its session ID. A Coordinator user provides its session ID and its ID when it notifies an event.
In the same way, a Coordinator user provides its session ID and its ID when it puts an object on the heap.
A Coordinator user provides its session ID and the ID of the object source when it gets an object from the heap.
The Coordinator environment supports one-to-many communication: more than one Coordinator user can subscribe to an event or get data from a source. The Coordinator environment also supports many-to-many communication because many sources can notify an event or put an object on the heap with the same ID.
A Coordinator user can use different Ids either when it acts as a source or when it acts as a destination.
Notes:
An ID should be a property that the users of the Control can set when they design their page.
The Session ID is the ID of the Session managed by the Web application server. This parameter is explicit to allow using the Coordinator in other environments where the Session object and the Session ID don’t exist.
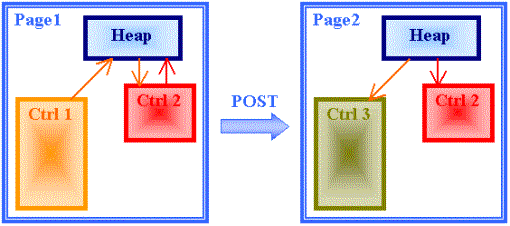
The diagram shows a typical use of the Heap management:
A Control Ctrl 1 put an object in the Heap.
A Control Ctrl 2 get the object posted by Ctrl 1. It can also put an object in the Heap.
Then the user navigates to another page that contains control Ctrl 2 and Ctrl 3.
The Control Ctrl 3 get the object posted by Ctrl 1 whereas Ctrl 2 get the object that the previous instance of Ctrl 2 has posted.
To get notified about events occurring in other Controls, a Control uses a Subscribe method.
It provides an object (typically itself) implementing a Callback interface.
The Callback interface has a single method, Notify, which is called by the Coordinator when the event source calls the Notify method of the Coordinator.
The Coordinator implements veto-able events: If one of the event destinations answers false in its Notify method, then the Coordinator answers false to the source Notify call.
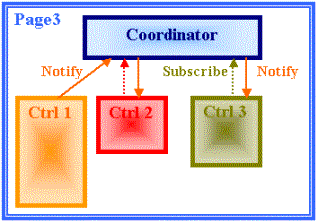
The diagram shows a typical use of the Event management:
A Control Ctrl 2 and a Control Ctrl 3 subscribe to get notified when Ctrl 1 notifies an event
The Control Ctrl 1 notifies an event
The Coordinator notifies the Controls Ctrl 2 and Ctrl 3
To participate to transactions involving more than one control, a Control uses a Subscribe method.
It provides an object (typically itself) implementing a Transaction interface.
The Transaction interface has two methods, Prepare and Commit, which are called by the Coordinator when the Transaction controller (another Control) calls the Commit method of the Coordinator.
A Transaction participant typically checks that everything is ready to allow the subsequent Commit to succeed, for instance that the Web services invoked in the Commit are available and when it is not the case returns false. Then the Coordinator doesn’t call their Commit method and returns false to the source Commit call.
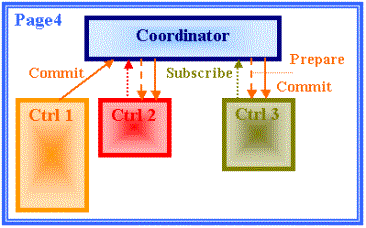
The diagram shows a typical use of the Event management:
A Control Ctrl 2 and a Control Ctrl 3 subscribe to participate to a transaction driven by Ctrl 1
The Control Ctrl 1 commits the transaction
The Coordinator calls the Prepare method of Ctrl 1 and Ctrl 2. If the Prepare of either Ctrl 1 or Ctrl 2 fails, the Commit call issued by Ctrl 1 returns false
Otherwise the Coordinator calls the Commit method of Ctrl 1 and Ctrl 2. If the Commit of either Ctrl 1 or Ctrl 2 fails, the Commit call issued by Ctrl 1 returns false
Many documents have been written about transaction databases and two-phase commit.
In this discussion we focus on their internal design to explain the problem that they solve. Then we show that the same approach can also help to coordinate Web service invocations.
Global transaction coordinators were invented to allow synchronizing updates on two or more database instances, not necessarily from the same vendor.
Each database implements a SQL API with verbs such as select, update, insert, delete.
Global transaction management requires also using a small API with three verbs, begin, commit and rollback.
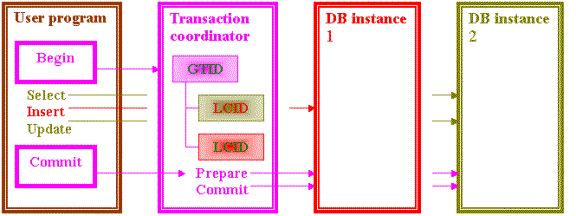
The diagram shows a typical global transaction processing.
The User program calls the Begin verb to create a global transaction. The most important task is not displayed on the diagram. The SQL APIs are notified that a global transaction has started. The auto-commit is disabled. The first request creates a local transaction on the DB instance and records its Local transaction ID (LCID) in the transaction coordinator.
The User program runs SQL requests. These requests are processed by the Database instances as usual
The User program calls the Commit verb. Then the Transaction coordinator first sends a Prepare request to each Database instance involved in the transaction. When a Database instance answers YES it means that the instance should be able to commit its local transaction. When all Database instances answer YES the Transaction coordinator sends a Commit request to each Database instance involved in the transaction. Then and only then the Database instances commit the changes.
This prepare-commit mechanism is also called two-phase commit. This mechanism is not 100% safe. If a Database host fails between the Prepare and the Commit then something called heuristic commit takes place: some changes can be committed and some are not. The user program cannot know because it has no way to differentiate a failure occurred just after the Commit (then the change is committed) and a failure occurred just before.
However the two-phase commit turned to be quite effective for three reasons:
RDBMSs are the main causes of failure at commit time
RDBMSs can accurately predict if they will be able to commit a set of changes
RDBMSs can make their prediction at a small resource cost
The latter points are worth an additional explanation.
Let’s assume that you have to predict that you will be able to append 100 bytes to a file. The only safe way is to write 100 bytes, perhaps binary zeroes. If you succeed then you probably will be able to replace these bytes by the real data. The implementation is not simple and you need to write on the disk two times instead of one. With RDBMSs the performance penalty is negligible because of their design.
A RDBMS is a pagination system. An uncommitted change can be written on disk whereas a committed change stays in memory. It doesn’t matters because the RDBMS also maintains change logs. What happens at commit is nothing more than logging.
Let’s consider the case of a Web page that uses two Web Application Controls. These Controls call Web services. The page also contains a Commit button. When the user clicks on this button we must invoke the Controls’ Web services hosted on different sites. Both or none of these Web services should be called. On Internet the main risk is that one host is not running. A two-phase commit can address this problem:
At Prepare time a control can instantiate a Web service proxy and check the Web service availability at a low CPU cost
At Commit time the control just needs to invoke the proxy method
The main weakness of this initial approach is that the availability check has a significant impact on the response time. This overhead is due to the network latency and is perhaps 100ms on average. PageBox hosted Web Services can reduce this overhead to 20ms. The Coordinator reduces it further with caching. On an active Web server many users query the same pages at about the same time. When a Control answered true to a Prepare request, the Coordinator can safely assume that a Prepare request on the same Control issued 100ms later would also succeed.
The API is implemented though two interfaces, Callback and Transaction, and three classes, Heap, CallbackCoordinator, TransactionCoordinator.
The Heap class implements three static methods, Get, Put and Remove.
Get has the following prototype:
object Get(string sourceID, string sessionID); |
Put has this prototype:
void Put(string sourceID, string sessionID, object toStore); |
Remove has this prototype:
void Remove(string sourceID, string sessionID); |
sourceID is the ID of the object source. It should be retrieved from a parameter set by the page designer.
sessionID should be unique for a user. It is typically the Web server session ID.
toStore is an object stores in the heap by Put and returned by Get
Notes:
More than one source can use the same sourceID to implement a many to many relationship
You can set the sessionID to any non-null value to make data available for all the Application. You can use this feature to implement the cache for data-dependent routing presented below
Remove removes an object added by Put to the Heap
The CallbackCoordinator class implements two static methods, Subscribe and Notify.
Subscribe has the following prototype:
Void Subscribe(string sourceID, string sessionID, string ID, Callback cb); |
sourceID is the ID of the Event source. It should be retrieved from a parameter set by the page designer.
sessionID should be unique for a user. It is typically the Web server session ID.
ID is the ID of the Subscriber invoker (a Event destination). It should be retrieved from a parameter set by the page designer
cb is an object provided by the Event destination and implementing the Callback interface
Notify has the following prototype:
bool Notify(string sourceID, string sessionID, object req, ref Hashtable resp, HttpRequest request); |
sourceID is the ID of the Event source. It should be retrieved from a parameter set by the page designer.
sessionID should be unique for a user. It is typically the Web server session ID.
req is an object that the Coordinator passes to the Notify method of the Callback interface
request is the HttpRequest object of the requestor. It is passed to the Notify method of the Callback interface. You can set it to null, for instance when you use the Coordinator outside an Application server
Notify is often used in one to many scenarios where a source notifies an event to many destinations, the destination list being unknown of the source. Each destination can return a response and the source can be interested by all responses. Therefore the Notify method populates a resp Hashtable passed by the caller (the source) with entries whose key is the destination ID and the value is an object, which can be
Returned by the destination
Or an Exception caught by the coordinator when it invoked the Notification method of a destination
Note:
If resp is null it means that the source is not interested by the destination responses
Coding style:
You must check the type of the resp elements.
In C# you can use the is verb:
Hashtable ht = new Hashtable(); if (PageBoxGrid.CallbackCoordinator.Notify(ID, Session.SessionID, null, ref ht, Request)) labStatus.Text = "Event accepted"; else labStatus.Text = "Event vetoed"; if (ht.Count > 0) { IDictionaryEnumerator ide = ht.GetEnumerator(); ide.MoveNext(); if (ide.Value is Exception) labInfo.Text = "[" + (string)ide.Key + "] " + ((Exception)ide.Value).Message; else if (ide.Value is string) labInfo.Text = "[" + (string)ide.Key + "] " + (string)ide.Value; } |
In this snippet we enumerate the resp elements, we check their value and we display them.
The TransactionCoordinator class implements three static methods, Subscribe, Commit and Rollback.
Subscribe has the following prototype:
void Subscribe(string sourceID, string sessionID, string ID, Transaction trans, int timeout); |
sourceID is the ID of the Commit source. It should be retrieved from a parameter set by the page designer.
sessionID should be unique for a user. It is typically the Web server session ID.
ID is the ID of the Subscriber invoker (a Commit destination). It should be retrieved from a parameter set by the page designer
trans is an object provided by the Commit destination and implementing the Transaction interface described below
timeout is the time between two Prepare invocations by the TransactionCoordinator
Commit has the following prototype:
bool Commit(string sourceID, string sessionID, object req, ref Hashtable resp, HttpRequest request); |
sourceID is the ID of the Commit source. It should be retrieved from a parameter set by the page designer.
sessionID should be unique for a user. It is typically the Web server session ID.
req is an object that the Coordinator passes to the Prepare and Commit methods of the Transaction interface
request is the HttpRequest object of the requestor. It is passed to the Prepare and Commit methods of the Transaction interface. You can set it to null, for instance when you use the Coordinator outside an Application server
Commit is normally used in one to many scenarios where a source commit a transaction involving many destinations, the destination list being unknown of the source. Each destination can return a response and the source can be interested by all responses. Therefore the Commit method populates a resp Hashtable passed by the caller (the source) with entries whose key is the destination ID and the value is an object, which can be
Returned by the destination
Or an Exception caught by the coordinator when it invoked the Prepare or the Commit method of a destination
Commit returns true if all Subscriber Prepare and Commit have succeeded and false otherwise.
Note:
Set timeout to 0 when you use the data-dependent routing of the ActiveNaming to retrieve a Web service URL. You must implement your own caching because the TransactionCoordinator doesn’t know your key range. You can use the Heap the implement your cache.
If resp is null it means that the source is not interested by the destination responses
If the Commit fails at the Prepare step then the resp Hashtable only contains the object returned by the failed Prepare. Otherwise the resp Hashtable contains the objects returned by the destination Commits.
Coding style:
You must check the type of the resp elements.
In C# you can use the is verb:
Hashtable ht = new Hashtable(); if (!PageBoxGrid.TransactionCoordinator.Commit(ID, Session.SessionID, null, ref ht, Request)) { if (ht.Count > 0) { IDictionaryEnumerator ide = ht.GetEnumerator(); ide.MoveNext(); if (ide.Value is Exception) labStatus.Text = "[" + (string)ide.Key + "] " + ((Exception)ide.Value).Message; else if (ide.Value is string) labStatus.Text = "[" + (string)ide.Key + "] " + (string)ide.Value; } } else labStatus.Text = "Transaction committed"; |
In this snippet we enumerate the resp elements, we check their value and we display them.
The developer of a PageBox control that register to a transaction should return in the Prepare and Commit resp parameter:
Either a string
Or an Exception
Or an object whose ToString method returns meaningful information
Rollback has the following prototype:
bool Rollback(string sourceID, string sessionID, object req, ref Hashtable resp, HttpRequest request); |
sourceID is the ID of the Rollback source. It should be retrieved from a parameter set by the page designer.
sessionID should be unique for a user. It is typically the Web server session ID.
req is an object that the Coordinator passes to the Rollback method of the Transaction interface
request is the HttpRequest object of the requestor. It is passed to the Rollback method of the Transaction interface. You can set it to null, for instance when you use the Coordinator outside an Application server
Rollback is normally used in one to many scenarios where a source rollbacks a transaction involving many destinations, the destination list being unknown of the source. Each destination can return a response and the source can be interested by all responses. Therefore the Rollback method populates a resp Hashtable passed by the caller (the source) with entries whose key is the destination ID and the value is an object, which can be
Returned by the destination
Or an Exception caught by the coordinator when it invoked the Rollback method of a destination
The Rollback function is to notify the transaction destinations that they must cleanup the changes they would have committed if Commit had been invoked. Rollback acts as a transaction delimiter. For a destination a transaction begins when
The destination subscribes to the Transaction
The source has committed or rollbacked a transaction, regardless of the transaction success or failure of the Commit or Rollback
Therefore the implementer of a destination class must clean the changes in all Transaction interface methods:
In Prepare when it is about to return false, because then Commit won’t be called
In Commit
In Rollback
The Callback interface has one method, Notify.
Notify has the following prototype:
bool Notify(string sourceID, object req, ref object resp, HttpRequest request); |
sourceID is the ID of the Event source
req is an object provided by the Event source when it invokes Notify
resp is an object returned by the Event target
request is the HttpRequest object of the requestor. When used in the context of an Application server it can be used to compute a Web service URI
Notify should return true in case of success and false otherwise.
When at least one subscriber returns false in the Notify method of its Callabck object the Notify method of the Event source returns false. It allows the subscribers to veto a change proposed by the Event source.
The Transaction interface has three methods, Prepare, Commit and Rollback.
Prepare has the following prototype:
bool Prepare(string sourceID, object req, ref object resp, HttpRequest request); |
Commit has this prototype:
bool Commit(string sourceID, object req, ref object resp, HttpRequest request); |
Rollback has this prototype:
bool Rollback(string sourceID, object req, ref object resp, HttpRequest request); |
sourceID is the ID of the Commit source
req is an object provided by the Commit source when it invokes Commit
resp is an object returned by the Commit destination
request is the HttpRequest object of the requestor. When used in the context of an Application server it can be used to compute a Web service URI
These methods should return true in case of success and false otherwise.
Notes:
If Prepare returns false, then the Coordinator returns false to the Commit source. The Coordinator doesn’t call Commit.
The Coordinator can call Commit without calling Prepare before if the entry is cached
Java PHP .NET
Reservation Controls Java controls
Polaris Grid Coordinator Grid V2
Distribution Installation NWS
Contact:support@pagebox.net
©2001-2004 Alexis Grandemange
Last modified